160 x 600
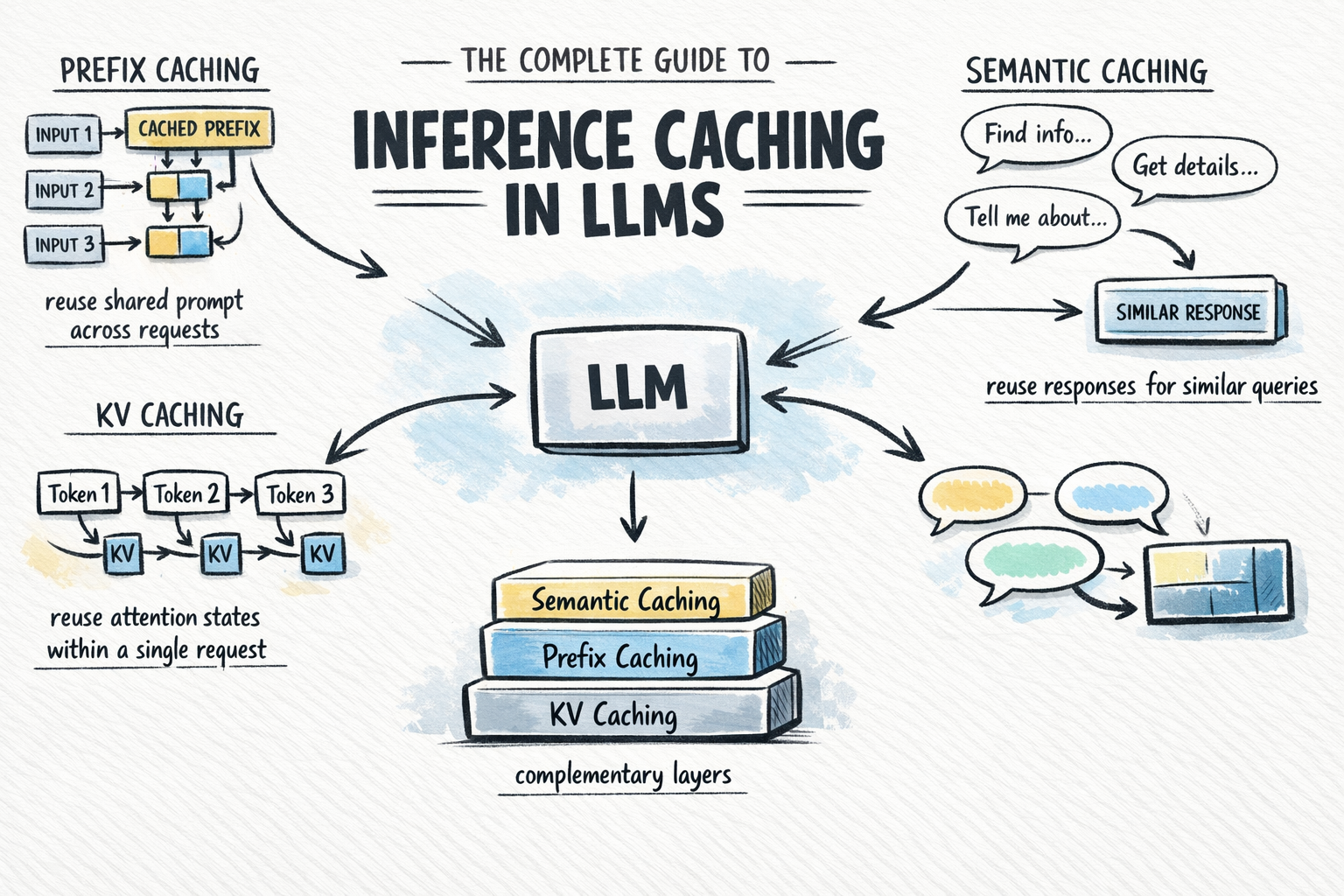
Modern web platforms are increasingly leveraging inference caching to enhance the performance and scalability of large language model (LLM) deployments. This capability centers on storing model outputs for specific prompts, thereby avoiding redundant computations during subsequent, identical or similar requests. The core technical value lies in reducing latency, lowering computational costs, and increasing throughput, particularly for applications with high volumes of repetitive queries.
From a business strategy perspective, implementing inference caching represents a critical optimization for monetized AI services. It directly translates to reduced infrastructure spend by utilizing existing compute cycles more efficiently, allowing organizations to serve more users with the same hardware footprint. This efficiency is a key competitive advantage, enabling more responsive user experiences and supporting dynamic pricing models that prioritize cost-effective delivery. The technology also facilitates a more sophisticated approach to resource allocation, where caching layers are intelligently managed based on request frequency and payload similarity.

Comments (0)
No comments yet. Be the first to start the discussion!



